BetterJournal (2)
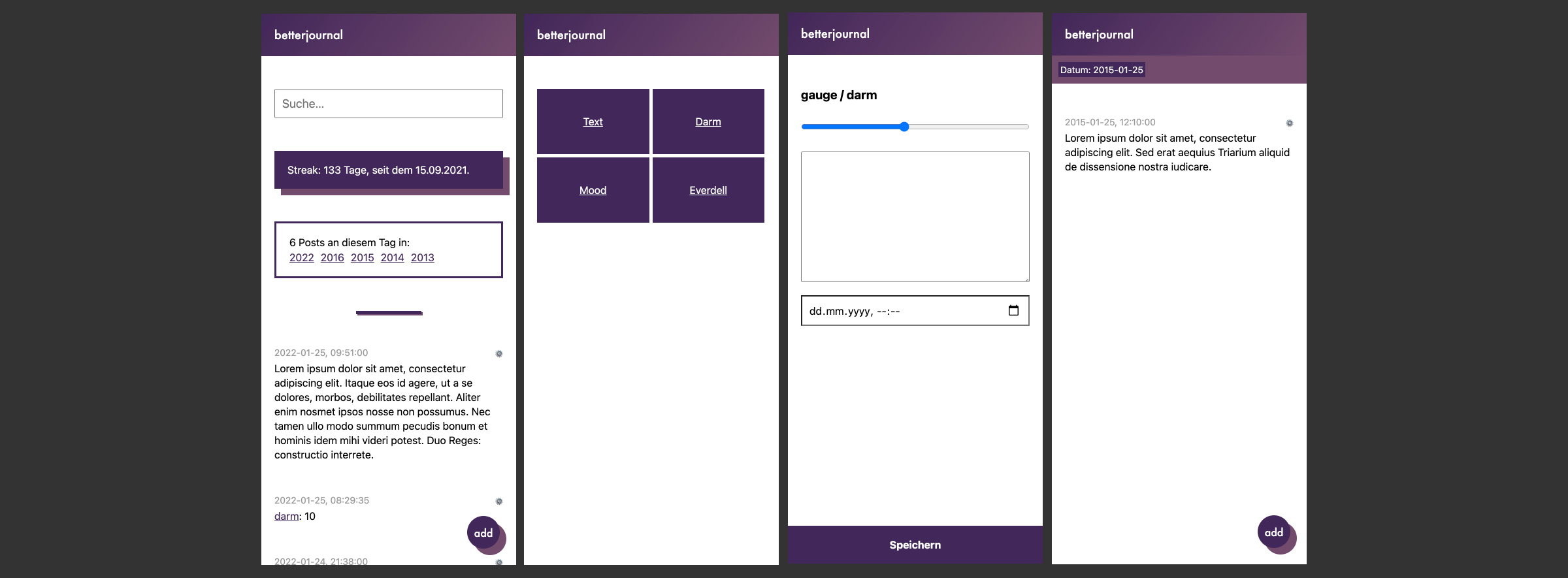
Zwei Tage und zwei weitere Kurz-Sprints weiter und mittlerweile ist es nicht mehr ganz so weiß und grau. Außerdem baute ich folgende Dinge ein, damit es Day One noch etwas näher kommt und benutzbar wird:
- Import der Day One-Posts
- Editierfunktion, weil ich mich auf dem Handy ständig vertippe, inklusive Datum, falls man doch mal was vergisst. Oder es schon nach Zwölf ist.
- Anzeige der aktuellen Streak, wichtig für die Motivation
- Auflistung der Posts von diesem Tag aus den unterschiedlichen Jahren
Ich hätte dazu jetzt gerne noch ausufernd was geschrieben und meine Arbeit beschrieben, aber letztendlich war nichts spannendes dabei. Also, vielleicht die Query für die Streaks, die benutzt nämlich eine Common Table Expression, wovon ich vorher noch nie hörte. Es ist quasi eine temporäre Tabelle, die man in der Query erzeugt und aus der man Kram herauslesen kann.
WITH groups AS (
SELECT RANK() OVER (ORDER BY date) AS row_number,
date,
date(date, "-" || RANK() OVER (ORDER BY date) || " days") AS date_group
FROM journals
group by date(date)
)
SELECT COUNT(*) AS days,
MIN (date) AS start,
MAX (date) as max_date
FROM groups
GROUP BY date_group
ORDER BY max_date DESC
LIMIT 1Natürlich habe ich das auch nur aus dem Internet zusammengesucht und auf meine Anforderungen angepasst, da wär ich ja niemals drauf gekommen.
Mit dem WITH groups () wird eine temporäre Tabelle erzeugt, die sich aus dem innenliegenden SELECT-Statement speist, die enthält die spannende Spalte date_group, in der die ganze Magie liegt.
Bisschen verwirrend, das alles date heißt, aber gut. Also, Folgendes: date() ist die SQLite-Funktion um ein Datum im Format YYYY-MM-DD auszugeben, und sie kann das Datum auch modifizieren. Hier nehmen wir also die Spalte date eines journals und ziehen davon die Zeilennummer (RANK() OVER (ORDER BY DATE)) ab. Die Pipes sind der SQLite-way um Strings aneinander zu pappen. Was ist jetzt die Magie daran, werdet ihr euch Fragen?
Angenommen, ihr habt eine Streak vom 1.9. bis zum 3.9. und eine vom 5.9. bis zum 7.9., hätte die Tabelle folgenden Inhalt:
- 1 – 01.09. – 31.08. (01.09. -1 Tag)
- 2 – 02.09. – 31.08. (02.09. -2 Tage)
- 3 – 03.09. – 31.08. (02.09. -3 Tage)
- 4 – 05.09. – 01.09. (05.09. -4 Tage)
- 5 – 06.09. – 01.09. (06.09. -5 Tage)
- 6 – 07.09. – 01.09. (07.09. -6 Tage)
Umso öfter ich es mir angucke, umso magischer finde ich es. Ich wünschte, ich käme auch mal auf so eine Idee und müsste es nicht erst auf Stack Overflow finden.
Hat man einmal diesen Teil, kann man nun aus der temporären groups Tabelle einfach die aktuelle Streak rausholen, in dem man nach date_group gruppiert und halt das Aktuellste nimmt.
Nach diesem kurzen Exkurs in die Welt von SQL, zurück zum Thema. Meine Todoliste wuchs beim Herumbasteln noch weiter, wie immer, typisches Ideenfeuerwerk, während man etwas baut und Spaß hat. Keine Davon ist jetzt allerdings so wichtig, dass ich sie dringend einbauen müsste, jetzt werde ich alles erstmal ein paar Tage oder Wochen Probelaufen lassen, hoffe ich. Man soll ja aufhören, wenn es am schönsten ist.
Eigentlich hätte ich auch Lust endlich mal wieder was auf Github hochzuladen, was tatsächlich auch andere benutzen können. Dazu müsste ich zumindest noch reindengeln, dass man die Defaults im “Hinzufügen”-Screen anpassen kann. Oder so. Mal sehen.