Ich habe den diesjährigen Urlaub mal wieder zum Anlass genommen, nach einer passenden Tasche für die ordentliche Verkabelung der eigenen Geräte zu Suchen und fand diese sehr schöne von tomtoc.
Da passt alles rein, was man mittlerweile so braucht, und das ist zum Glück echt gar nicht mehr viel: Zwei 65-Watt-GaN-Charger und ein 100-Watt-GaN-Charger von UGREEN, vier USB-C-Kabel mit einer Länge von drei Metern, damit man auch hinter jedes Sofa kommt. Der einzige ungewöhnliche Ausreißer ist das Ladekabel für die Apple Watch.
Seit ein paar Jahren höre ich den Podcast von Anke Engelke und Kristian Thees und es ist ein Highlight meiner Woche, oder eher zwei Highlights, denn es gibt zwei Folgen! Leider hat das SWR sich nun entschieden, den Podcast einzustellen. Ein weiterer Dauerbrenner, der im Jahr 2026 wohl meinen Feed verlassen wird. Schade!
In den letzten Wochen häufen sich auf Hacker News und ähnlichen Plattformen die Posts, in denen Leute erzählen, wie sie sich zurück besinnen auf die Zeit, ohne Spotify. Damals als wir alle noch CDs kauften, selber rippten und sicherlich keine 100GB großen MP3-Sammlungen auf LAN-Parties von Freunden überspielten.
Da alles, was mir mehr Arbeit macht, irgendwie mit mit resoniert, fand ich das natürlich interessant. Auf meiner NAS befindet sich ja sogar noch meine Musiksammlung aus alten Tagen, die ich sogar mal durch iTunes Match (wer erinnert sich noch?) legitimiert und qualitativ hochgestuft habe.
Nun wäre es aber ja langweilig, einfach die MP3s zu nehmen, sie in Jellyfin zu packen und mir einen Player zu suchen, der das als Quelle benutzen kann.
Inspiriert von einem anderen Artikel im Internet, der mit einem Raspberry PI und FM-Transmitter eine eigene Radiostation mit seiner Musik baute, dachte ich mir, sowas will ich auch. Natürlich ohne Raspberry PI und FM-Transmitter, aber einfach ein Stream, der die ganze Zeit läuft, wo ich mich kurz von überall reinschalten kann, das wäre super. Kein Überlegen, was ich eigentlich hören will oder Playlists erstellen.
In der ersten Version baute ich, mit Hilfe von Claude Code, erstmal eine Python-App, die ein Verzeichnis mit Musik indiziert, zufällig Lieder auswählt und sie an eine Icecast-Instanz schickt, zu der ich mich dann verbinden kann. Das funktionierte schonmal ziemlich gut. Im ersten Schritt fand ich erstmal nur meine die ärzte-Ordner, ich habe jetzt also drei Tage lang erstmal nur alte Live-Alben gehört und freue mich jetzt schon über diese Entscheidung.
Ich bin gespannt, was ich in den nächsten Monaten alles noch an Musik wiederentdecken werde, die ich bei Spotify nicht mehr hatte. Bei den ärzten z.B. habe ich ja sehr viele von den 2012er Konzerten, wo man die USB-Sticks am Ende kaufen konnte und das ist natürlich alles ganz exzellenter Content.
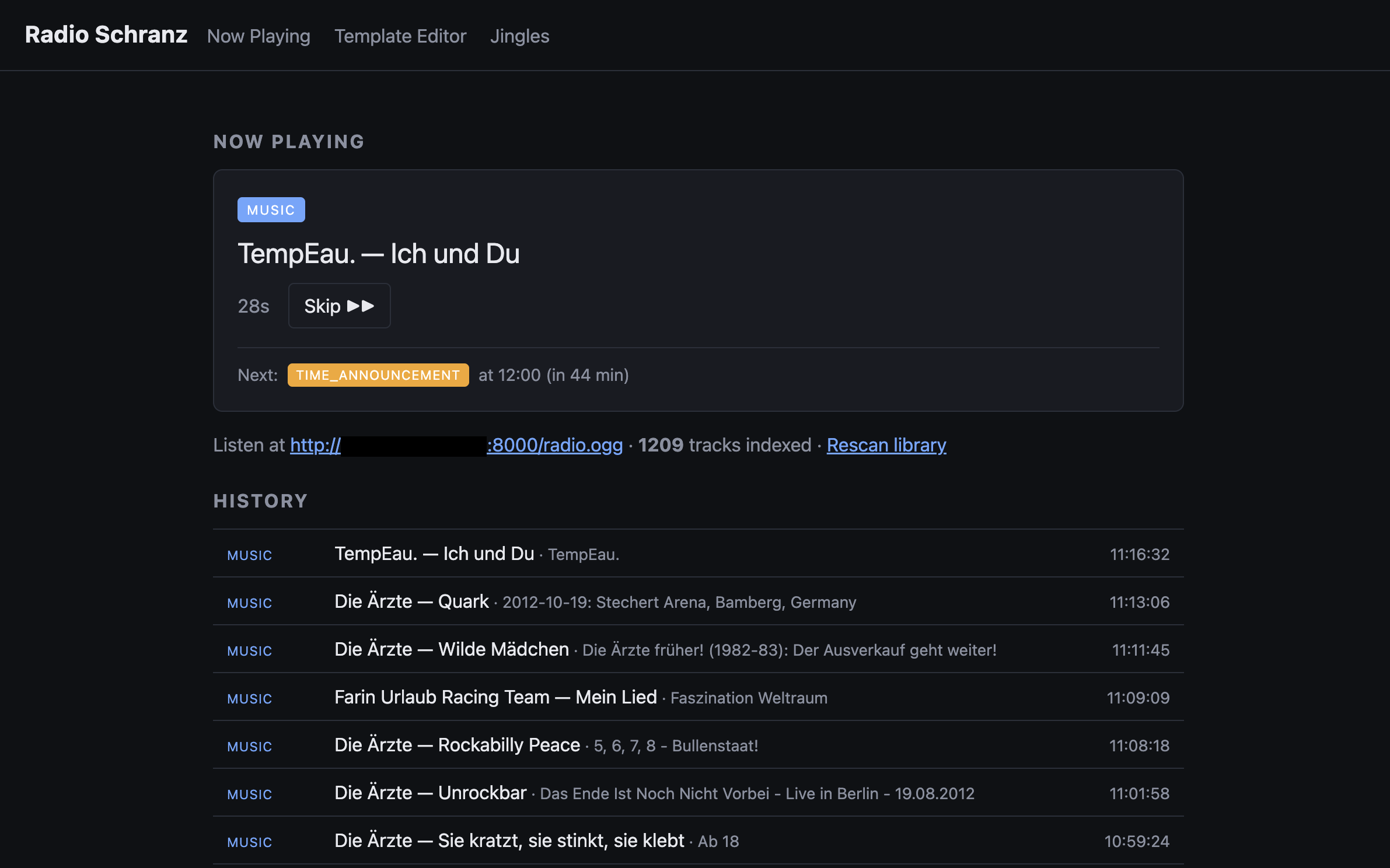
Sehr technisches Controlpanel
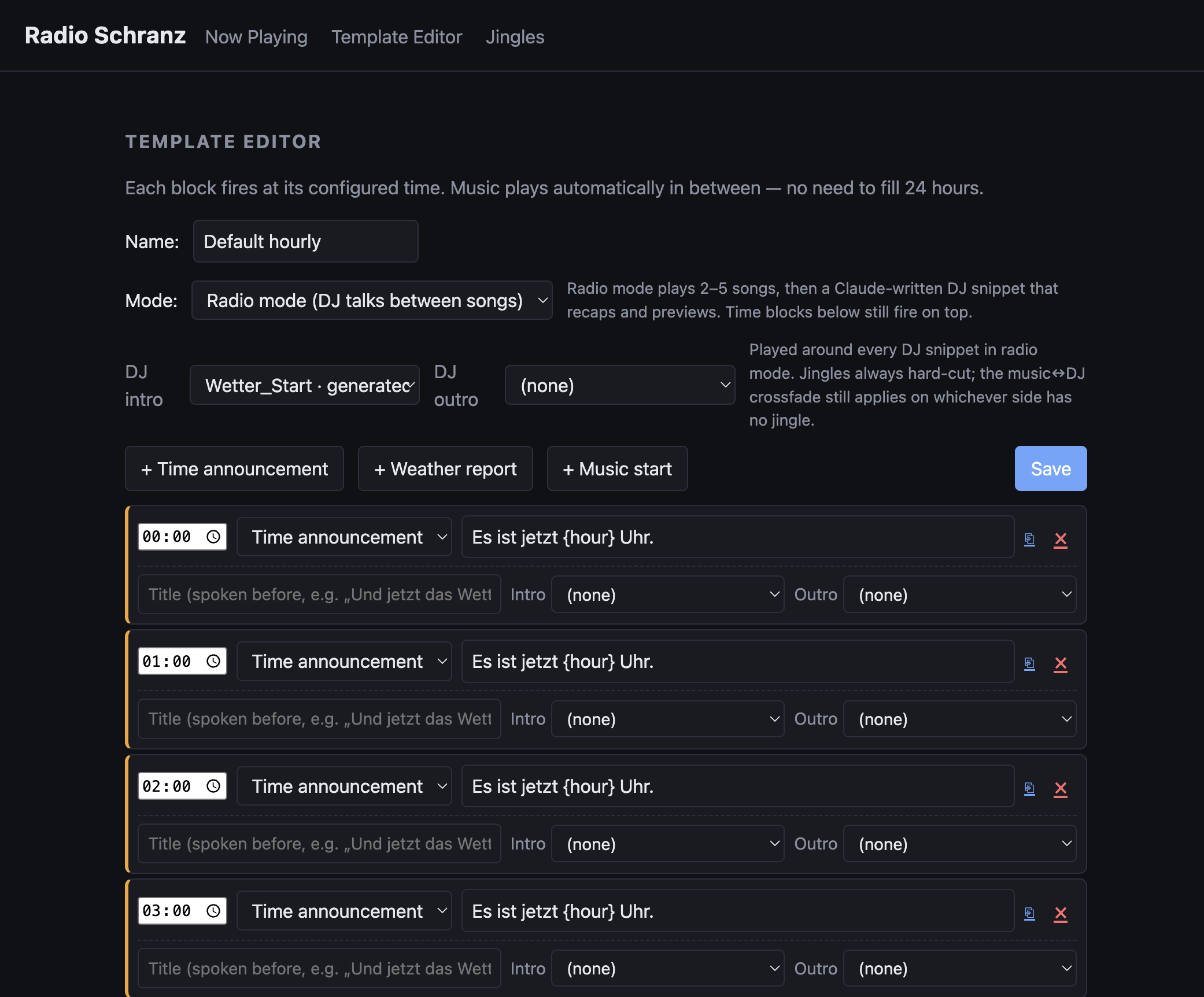
Um alles noch etwas Radio-mäßiger zu machen, baute ich noch eine Art Timetable ein, in dem man verschiedene Blöcke definieren kann, die zu bestimmten Zeiten gespielt werden, jetzt bekomme ich jede Stunde die aktuelle Zeit angesagt und ein paar mal am Tag einen Wetterbericht, was natürlich Quatsch ist, aber die Sache auch etwas auflockert. Für die Text-to-Speech-Synthese nutze ich Piper mit der Thorsten-Voice. Ich finde dafür, dass das alles ziemlich performant lokal läuft, sind die Ergebnisse echt nicht schlecht.
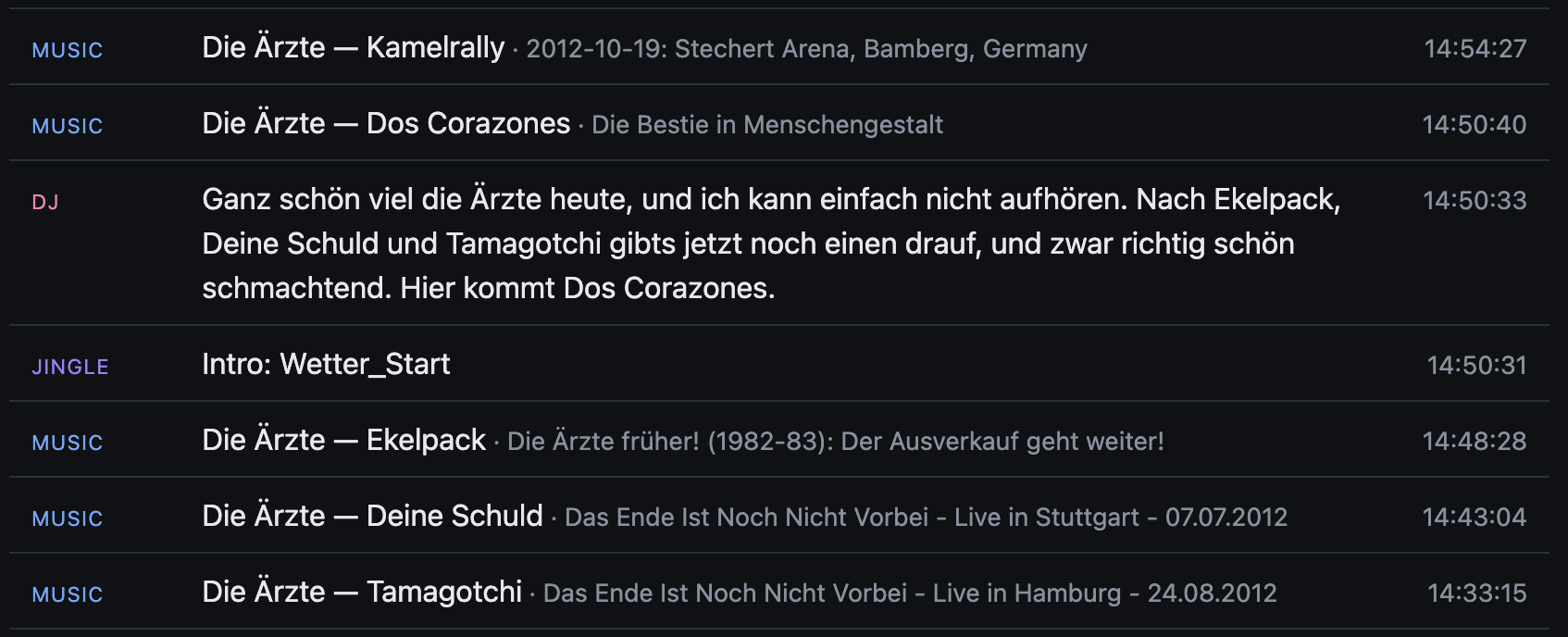
Für das absolute Radiofeeling brauche ich nun natürlich noch ein paar sinnlose Ansagen, die alle 2-5 Lieder kommen. Dafür habe ich einen Prompt geschrieben, an den ich noch die letzten und nächsten Lieder dran hänge. Die OpenAI-API liefert dann oft eine halbwegs witzige radiomäßige Ansage, die mir wieder per Thorsten-Voice eingespielt wird. Nach stundenlangen Ärzte-Sessions merkt man auch, wie das LLM langsam verzweifelt.
Natürlich werden alle Sachen, die einen API-Request an OpenAI schicken nur ausgeführt, wenn ich auch wirklich zum Icecast-Server verbunden bin, sonst wäre das ja Quatsch. Klappt aber echt gut!
Gestern habe ich nun versucht, mehr Musik hinzuzufügen und musste feststellen, dass ich vor ein paar Jahren wohl einen Fehler begangen habe. Ich kopierte meinen Musik-Ordner von der NAS auf die Plex-SSD, damit ich den Kram in Plex parat habe. Leider scheint der Kopiervorgang da nicht komplett durchgelaufen zu sein, was ich aber nicht merkte. Ich entfernte also alles von der NAS, da die Daten ja im nächsten Backup von der Plex-SSD automatisch zurückkommen würden und ich nichts doppelt haben wollte.
Damit habe ich natürlich 90% meiner Musiksammlung vernichtet, quasi alles, bis auf den die ärzte-Ordner. Zum Glück benutze ich das Synology HyperBackup und konnte bis in den Januar 2023 zurückspringen und einfach den gesamten Order wieder herstellen, nice! Das erste mal, dass ich ein Backup wirklich brauchte und es auch funktionierte.
Ich habe nun also langsam angefangen, ein paar weitere Interpreten in mein Radio aufzunehmen. Im nächsten Schritt werde ich also mal mit Claude besprechen, wie wir einen vernünftigen Algorithmus finden, der für genug Abwechslung sorgt und nicht nur stundenlang weiterhin die ärzte spielt, nur weil es ein Großteil der Dateien ist. Außerdem fänd ich es auch gut, wenn es zumindest genremäßig Cluster gibt, damit er nicht ganz wild von Reinhard Mey zu Scooter, zu PUR, zu X JAPAN und Casper springt. Schauen wir mal, wie gut das klappt.
(Da ich vor weit über zehn Jahren aufhörte, meine Sammlung zu pflegen, fehlt da auch einfach quasi alles an Musik, was ich aktuell höre, das wird auch noch ein teures Erlebnis, das auf einen aktuellen Stand zu hieven. Vielleicht muss ich mal auf ein paar Flohmärkten CDs kaufen)
Seit ein paar Wochen habe ich einen Boox Palma (danke, Kevin), weil ich dachte, so ein kleines süßes E-Ink-Gerät zum Lesen von Büchern ist sicher ganz nett, damit man nicht immer auf das leuchtende iPhone guckt.
(Ich habe auch einen Kindle, aber ich mag das kleine Format lieber)
Nun liegt der Palma leider meistens beim Bett und natürlich trage ich keine zwei Geräte im Handyformat gleichzeitig mit mir herum. Es ist mir also schon öfter passiert, dass ich, z.B. auf der Toilette, gerne ein paar Seiten lesen wollte, aber nicht konnte.
Dieses Problem sollte sich ja lösen lassen, dachte ich mir. Ein paar findige Menschen aus dem Internet werden dafür sicherlich eine Softwarelösung entwickelt haben. Also suchte ich folgendes:
Eine self-hostable Web-App für die Bücher und den aktuellen Lesestand
Eine App für’s iPhone, die mit dieser Web-App kommunizieren kann und alle Features unterstützt.
Auf dem Palma benutze ich KOReader, eine wunderbare Open Source Software, die tausend Funktionen und schreckliche UX hat. KOReader unterstützt OPDS als Katalog-Quelle für Bücher und zum Syncen des States den KOReader-Sync, den man entweder an die offizielle API anbinden kann, oder an einen eigenen Server. Natürlich sind das zwei verschiedene Sachen.
Ich installierte also zunächst einmalKomga. Das sieht scheiße aus und ist eine Java-App, aber dank Docker ist das ja egal. An sich funktionierte es, auch wenn ich nicht verstehe, warum man nicht einfach ein .epub in das Webinterface droppen kann, um es hochzuladen. Man muss seine Dateien feinsäuberlich in eine ordentliche Ordnerstruktur ablegen, damit sie korrekt erkannt werden. Eigentlich ist das natürlich für Comic- und Manga-Raubkopien gebaut und ich fand in der Doku gar keine Beschreibung, wie genau ich jetzt da die Bücher ablegen muss, damit sie richtig erkannt werden.
Da ich die Konnektivität testen wollte, machte ich also fürs Erste mit einem einzelnen erkannten Buch weiter. Ich fügte alles in KOReader ein und leider bekomme ich bei “Push read state to server” einfach einen “Unknown Error” und in den Logs von Komga taucht nichts auf. Schade!
Als nächstes probierte ich Kavita. Das sieht ein bisschen besser aus, ich kann aber auch hier keine Bücher einfach hochladen. Die Anbindung an KOReader klappt gut, ich kann auch fehlerlos den aktuellen Progress im Buch pushen. Nun machte ich mich auf den beschwerlichen Weg eine iOS-App zu finden, die mit den ganzen APIs umgehen kann.
Es gibt zwar viele Apps, die OPDS unterstützen, aber ich fand keine die die “Progress Sync”-Extension kann und nur eine, die eine KOReader-API dafür anbinden kann. Diese App heißt Readest, ist immerhin Open Source, aber auch im App Store. Für eine Cross-Plattform-App ist sie ganz ok und man könnte sicher ganz gut drin lesen, doch leider… funktioniert der KOReader-Sync nicht. Man kann zwar alles einrichten, und wenn man ein Buch öffnet, kommt sogar ein Popup, in dem steht, dass der lokale Status sich vom Server unterscheidet, wenn man auf Update klickt, passiert aber einfach gar nichts.
Schade, anscheinend ist das doch alles etwas zu wackelig.
Nachdem ich nun also ein paar frustrierende Stunden verbracht habe (es ist sehr anstrengend sehr lange komische API-Sync-URLs auf dem Boox Palma, mit seiner komischen E-Ink-Tastatur, abzutippen), habe ich keine Lust mehr. Die Zeit hätte ich auch besser mit Lesen verbringen können.
Also entweder schaue ich mal, wie man die Kindle-App auf dem Palma installiert, oder ich lese einfach zwei verschiedene Bücher gleichzeitig. Da kann man halt nichts machen im Jahre 2026.
Spätestens nach dem Release von Nackt II von Subway to Sally habe ich mich geärgert, dass ich es damals nicht schaffte, zu einem der Konzerte zu gehen. Akustische Versionen, Live, bestuhlte Locations. Was für eine wunderbare Kombination! Neon habe ich ebenfalls verpasst, von dem Konzept bin ich aber bis heute auch noch nicht so ganz überzeugt.
Wenn ich Subway to Sally höre, dann sind es zu 90% also diese Live-Akustik-Alben und daher war ich ganz besonders erfreut, dass sie eine dritte Nackt-Tour ankündigten und kaufte mir sofort ein Ticket. Anfang Mai war es nun soweit.
Das Konzert war auch sehr gut! Ich war ja schon seit längerer Zeit nicht mehr auf einem richtigen Konzert, aber es ist schon ganz nett, die Lautstärke am ganzen Körper zu spüren. Ich hätte natürlich daran denken können, meine Gehörschutz-Dinger mitzunehmen, zwischendurch war es doch ganz schön laut.
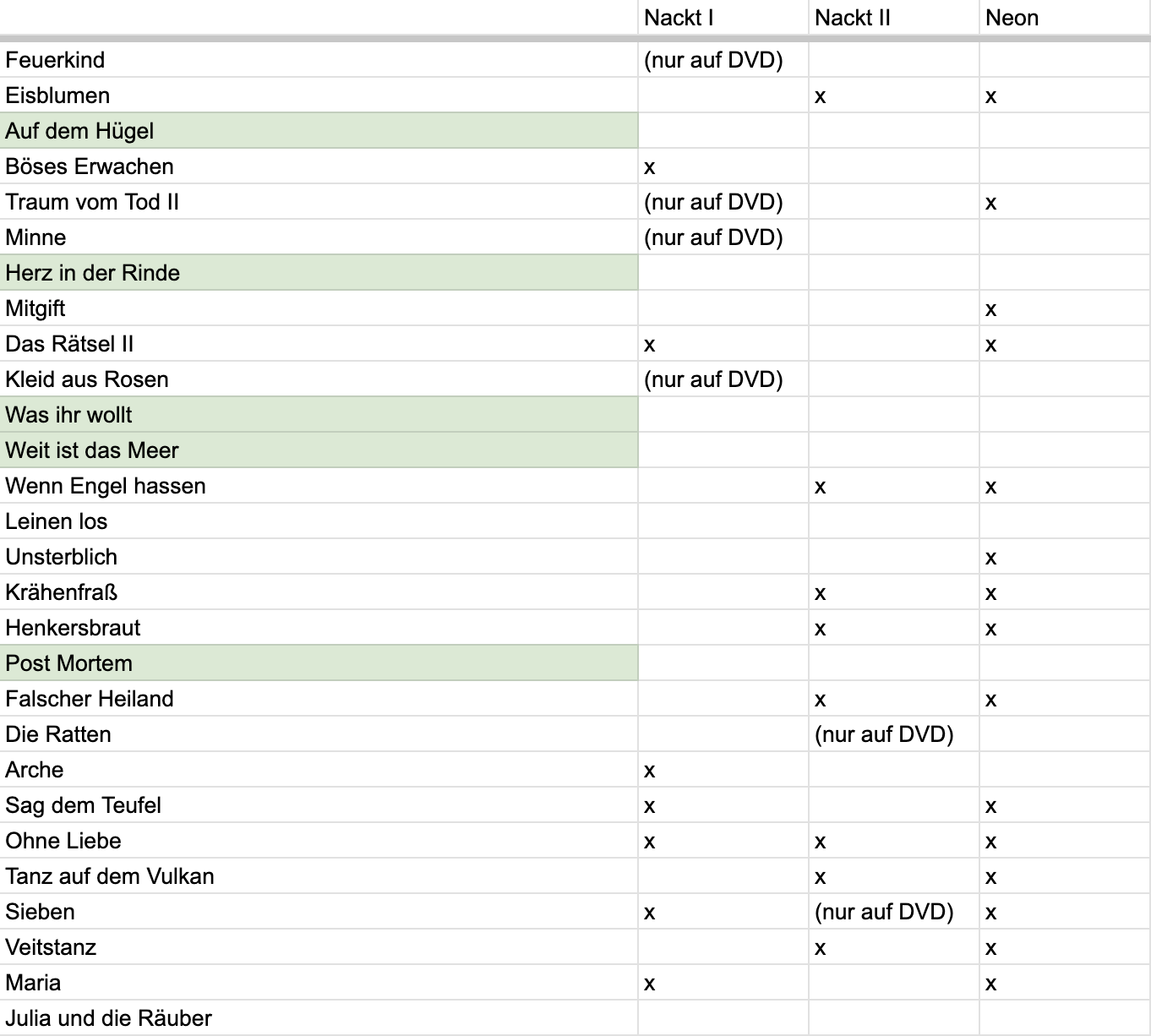
Die Setlist war fast nur mit alten Liedern befüllt. Ich habe hier mal eine Übersicht erstellt, weil es mich selber einfach interessiert hat (Achtung Setlist-Spoiler, aber die Tour ist ja eh vorbei):
Wir man sieht gab es nur fünf neue Songs, zwei von Post Mortem und drei von Himmelfahrt. Das 2019er Album “HEY!” hat es damit gar nicht in die Setliste geschafft. An sich fand ich das Konzert gerade deswegen natürlich schön. Es kam der ganze Kram, den ich eh schon kenne und viel höre und das war alles wunderbar, andererseits sind es ja gerade die Nackt-Alben die mich bei manchen Liedern erst dazu brachten, sie überhaupt zu mögen, von daher hätte ich es schön gefunden, wenn sie noch ein paar mehr von mir bisher unbeachteten Liedern eine Akustikversion gegeben hätten.
Außerdem frag ich mich immer, wie sich das als Band, die seit 30 Jahren auf der Bühne ist, anfühlt, wenn man immer nur die gleichen alten Schinken spielt. Der Großteil der Song ist ja über 15 Jahre alt.
Ganz davon abgesehen fand ich es ein überraschend durchmischtes Publikum. Irgendwie scheinen sie auch noch die neue Generation anzusprechen. Hören die wohl die neuen Alben und sind am Ende enttäuscht, dass nur alter Kram kommt, oder hört man als 17-jähriger Goth-Anwärter auch direkt die Klassiker? Wer weiß, ich hatte nichtmal ein schwarzes T-Shirt an.
Auch wenn mir der Abend sehr gut gefallen hat und ich 2027 zur angekündigten “Nackt III - Finale”-Tour sicher nochmal hingehen werde, muss ich trotzdem noch erwähnen, dass der Sound ganz schlecht abgemischt war und Ingo Hampfs Gitarren und Lauten durchweg viel zu laut waren, das wäre aber auch mein einziger Kritikpunkt.
Vor ein paar Jahren habe ich angefangen Joggen zu gehen, mit unterschiedlichem Erfolg. Während ich es in manchen Jahren schaffte, zumindest im Sommer, mal drei Wochen durchzuhalten, joggte ich 2024 genau einmal. Das merkte ich, als ich Ende 2025 mal in meinen Runkeeper-Account schaute.
Jedenfalls fiel mir da auf, dass ich 2025 noch kein einziges mal joggen war und fühlte mich gechallenged. Zumindest das eine Mal sollte ich es wohl schaffen, meine müden Beine etwas zu bewegen. Ich ging am 12. Dezember also los und lief eine Runde. Tatsächlich stellte sich dann bis zu den Weihnachtsferien eine kleine Routine ein. Montags, Dienstags, Donnerstags und Freitags.
Im nächsten Schritt schaffte ich es sogar, die ganze Sache ins neue Jahr zu retten. Mittlerweile habe ich einen kleinen Meilenstein erreicht: ich bin in 2026 insgesamt 100km gelaufen. Hätte das alles auch schon Anfang April schaffen können, aber dann war ich kurz krank und hier und da kamen andere Sachen dazwischen, die mich davon abgehalten haben, die letzten 3.6km hinter mich zu bringen.
Auf der einen Seite bin ich ein bisschen stolz auf mich, dass ich das jetzt über vier Monate lang durchgezogen habe. Jetzt sind 100km auch nicht besonders viel, jeder vernünftige Jogger schafft das ja an einem Wochenende mit zwei kurzen Marathonläufen, aber es dürfte immerhin die konstanteste und am längsten andauerndste sportliche Betätigung meines Lebens sein.
Leider macht es mir wirklich gar keinen Spaß. Meine normale Laufrunde ist so ungefähr zweieinhalb Kilometer lang. Zum Vollenden der 100 Kilometer brauchte ich am letzten Tag nur noch 1100 Meter und ihr könnt raten, wer in kleinen Kreisen um den Block lief um nicht einen Zentimeter zu viel zurücklegen zu müssen. (Bin am Ende doch 100 Meter zuviel gelaufen, weil sicher ist sicher und nichts wäre schlimmer gewesen, als am nächsten Tag nochmal loszulaufen, weil mir 22 Meter fehlten).
Ich bin sehr faul. Manchmal denke ich, dass es echt schlau wäre, einmal in der Woche auf so einem Rollbrett aus der KFZ-Werkstatt durch die Wohnung zu fahren, um die Sachen einzusammeln, die auf dem Boden liegen, weil ich im Laufe der Woche zu faul war mich zu bücken, um sie aufzuheben. Im Nachhinein kann ich mir gar nicht mehr vorstellen, wie ich es geschafft habe, so viele Tage am Stück laufen zu gehen. Teilweise sogar bei Minusgraden!
Was das angeht bin ich also sehr froh, es tatsächlich geschafft zu haben, andererseits hätte ich mir gewünscht, dass sich doch zumindest ein bisschen Spaß an der Sache einstellt. So muss ich mich wohl, wie immer, erstmal wieder extern motivieren, weiter zu machen, z.B. indem ich mir mal ein paar neue Schuhe kaufe, die nicht meine drei Jahre alten Alltags-Sneaker sind. Ich hoffe, diese Investition bringt mich über die nächsten 100km und dann schauen wir mal weiter.
Authentik funktioniert zwar gut, ist aber auch recht komplex. Es unterstützt natürlich Passkeys, aber um das zu erreichen, was ich wollte – nämlich, dass man sich direkt von der Startseite mit einem Klick per Passkey einloggen kann, statt ihn nur als zweiten Faktor nach der Passwort-Eingabe zu nutzen, braucht es ein paar Klicks.
Leider wurde ich aus der Doku nicht so richtig schlau. Wenn man danach googelt findet man sowieso nur tausende Reddit-Posts, die alle dieses Video von einem User namens Cooptonian. Ich… versuchte also seinen Anweisungen zu folgen (was extrem nervig ist, wenn es ein Video ist, das nur zeigt, wo im Web-Interface man drücken muss, warum ist das kein Blogpost.) und es klappte nicht.
Ich fand mich also erstmal damit ab und versuchte es ein paar Wochen später nochmal. Klappte immer noch nicht.
Gestern versuchte ich es nochmal, ich ging das Video Frame-by-Frame durch und verglich jede Einstellung. Mit Erfolg: Jetzt klappt der Login mit Passkey. Toll! Keine Ahnung, woran es lag, tho. Ich habe beim letzten sehr genauen Versuch nichts gefunden, was ich in den vorherigen Versuchen falsch gemacht haben könnte.
Seit Ewigkeiten bin ich auf der Suche nach einer funktionierenden Google Sheets Alternative. Mittlerweile habe ich sie, wieder einmal dank Kevin, wohl gefunden: ONLYOFFICE.
Ich kannte die Software natürlich irgendwie, aber in meinem Kopf war es einfach nur ein weiterer schrottiger Fork von OpenOffice. Aber weit gefehlt: Es ist ziemlich perfekt. Es startet auf meinem Mac schnell und die TTNS (Time to new Spreadsheet) ist auf jeden Fall maximal so 2-3 Sekunden. Perfekt. Ich mache mich jetzt mal daran, meine ganzen Sheets herunterzuladen und zu öffnen. Hier und da gibt es noch ein paar kleine Sachen, die leicht kaputt sind, aber insgesamt sieht das schon sehr gut aus.
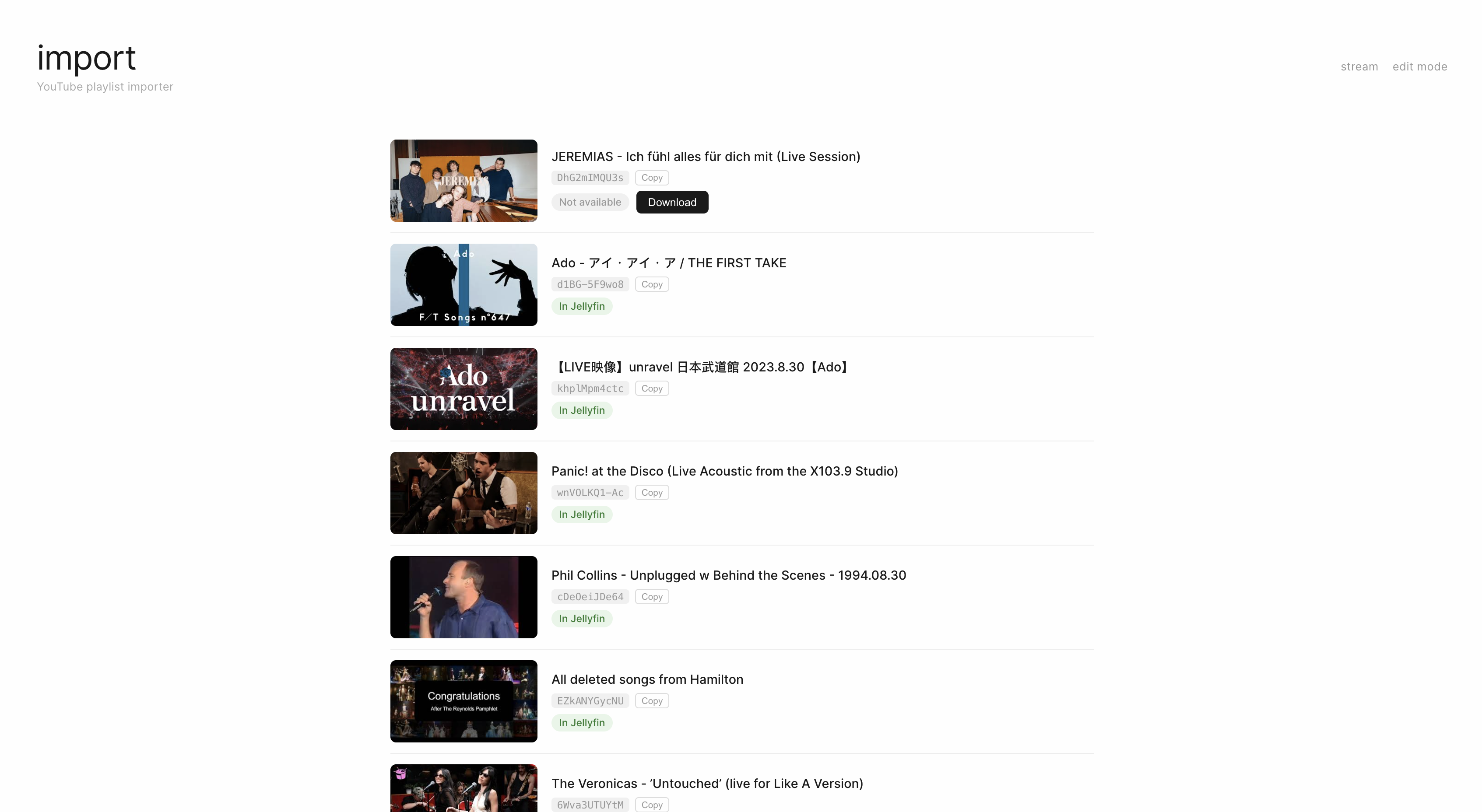
Wie geschrieben wechselte ich auf Jellyfin und ging im dem Zug auch ein Thema an, was mir schon länger im Hinterkopf war, was sich dank Claude Code aber mal wieder in kürze lösen lies. Bereits vor drei Jahren baute ich ein Script, was mit Youtube-Videos aus einer speziellen Playlist herunterläd. Witzigerweise schrieb das damals schon ChatGPT, kurios, dass das damals schon so gut funktionierte.
In der Zeit haben sich über 200 Videos angesammelt und natürlich ging ich nie durch, um sie mal vernünftig zu sortieren und zu benennen. Ich hab sie eigentlich auch nie angeschaut, da mein Plex immer nur so mittelgut funktionierte und der Gang zu Youtube viel kürzer war.
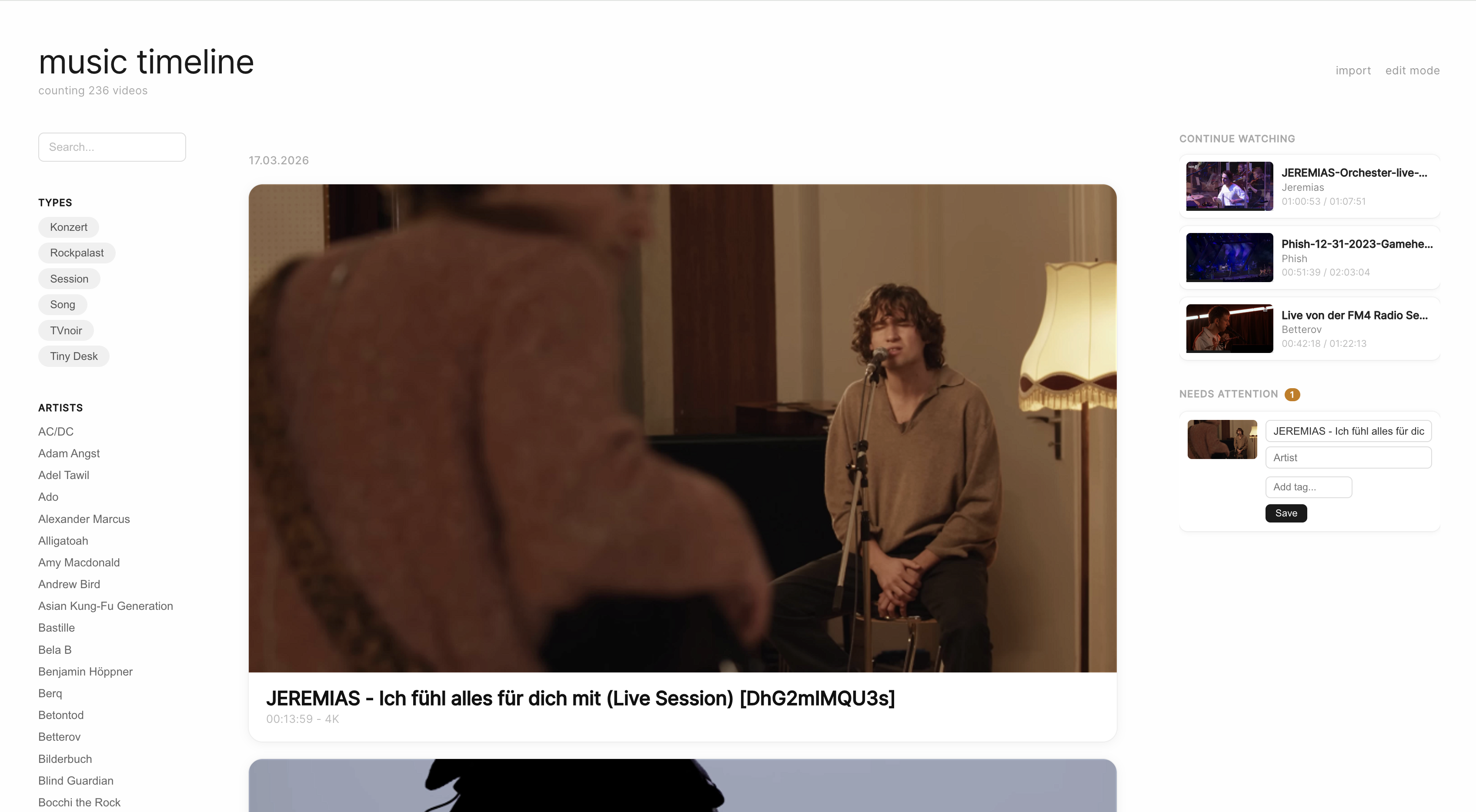
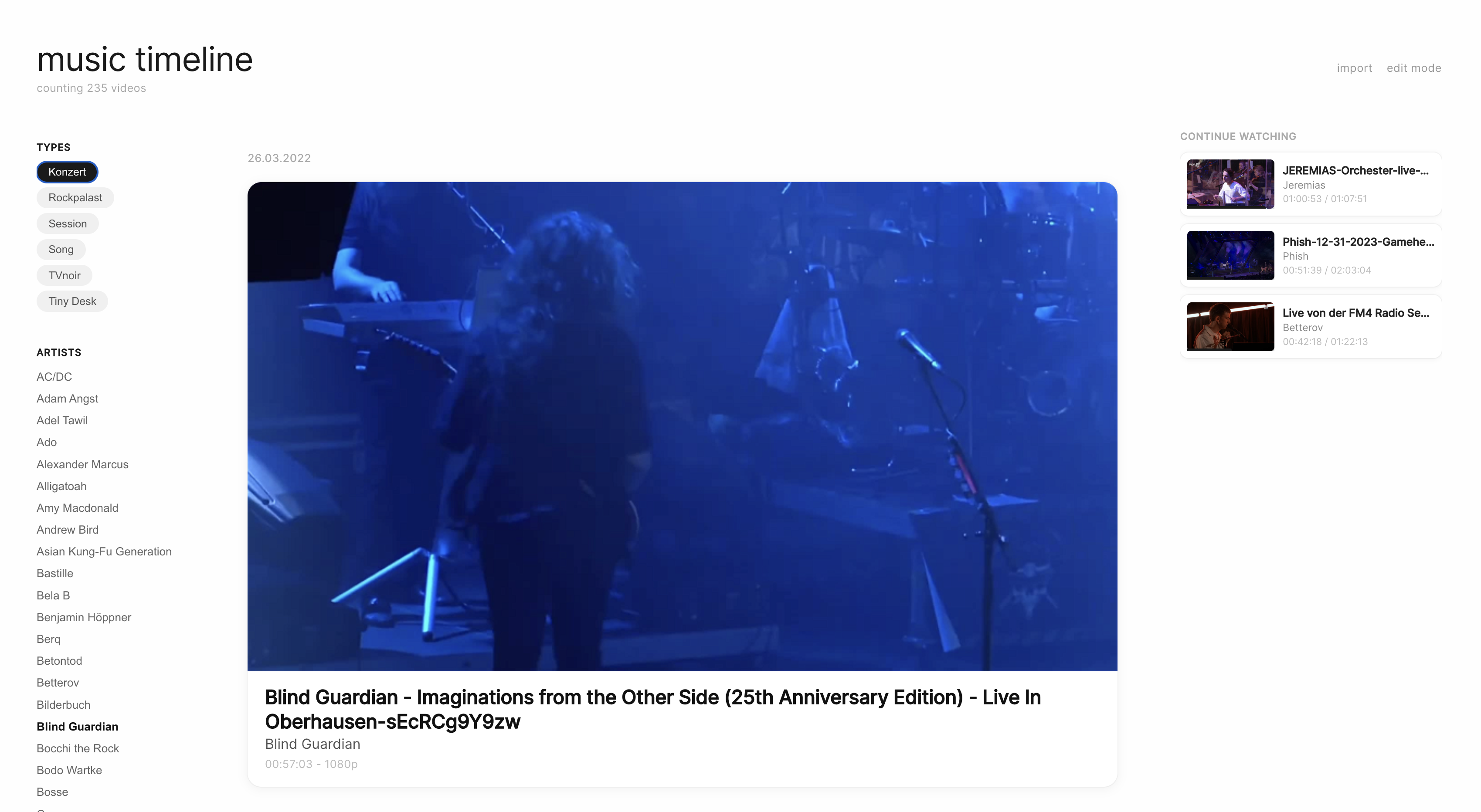
Aber ich will ja eigentlich nicht mehr ständig Traffic verschwenden, wenn ich die Videos sowieso lokal gespeichert habe. Ich habe mir also ein Frontend bauen lassen, das die zu heruntergeladenen Videos schön in einem Stream darstellt, inklusive Filter-Funktion nach Interpret und von mir vergebenen Tags.
Ebenfalls integriert ist die Download-Funktion, der zeigt mir alles in der Playlist an und ich kann es mit einem Button herunterladen. Eigentlich lief das ja als Cronjob, aber ab und zu kommt es halt doch zu Fehlern, daher habe ich mich hier erstmal wieder für ein manuelles klicken und überwachen entschieden. Soviel füge ich jetzt auch nicht der Liste hinzu.
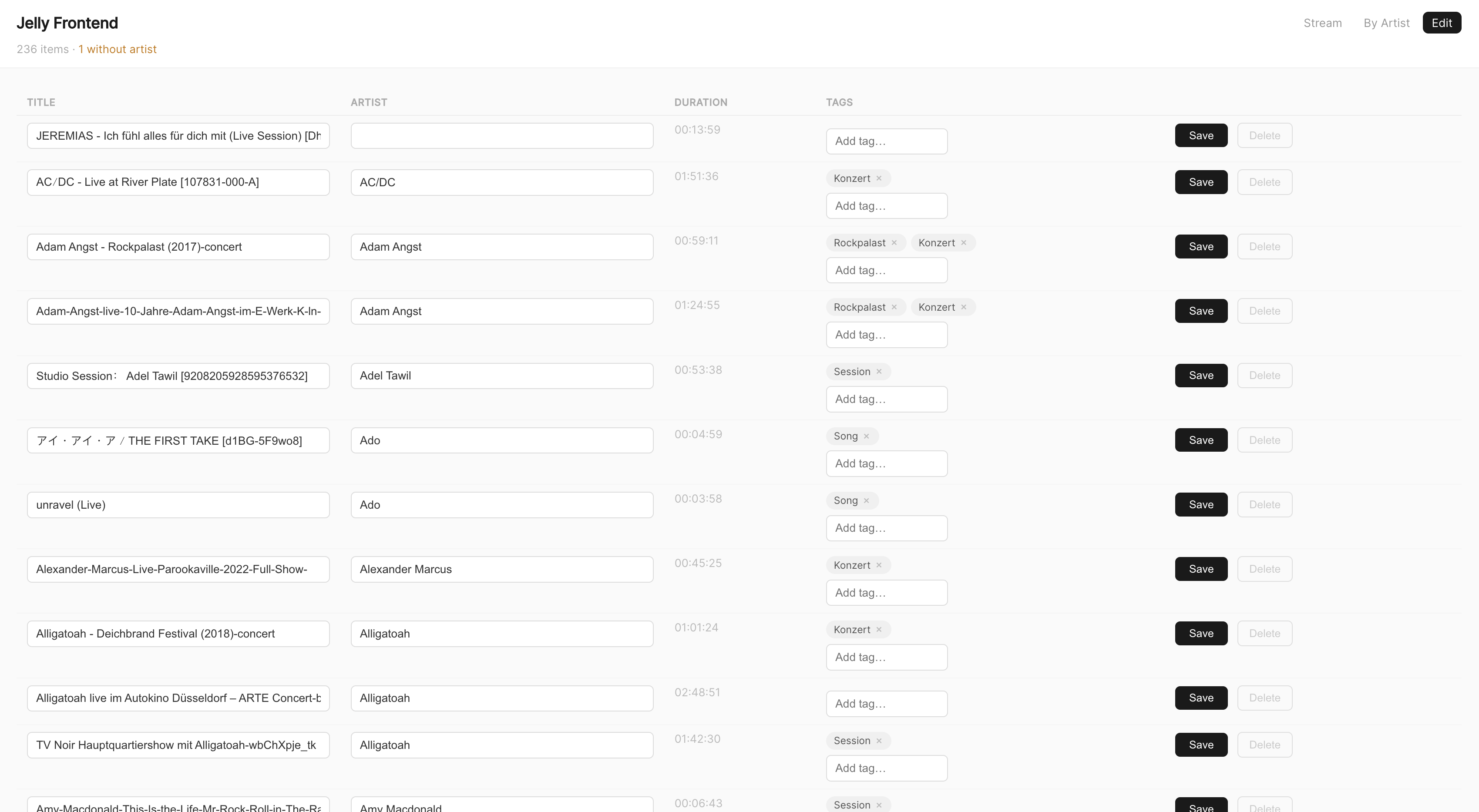
Als letztes gibt es noch die etwas hässliche aber sehr praktische Edit-Ansicht, wo ich direkt Titel, Artist und Tags vergeben kann. Das ist nämlich in Jellyfin direkt auch verdammt umständlich. (Dazu kommt, dass man in Jellyfin immer erstmal die Bibliothek neu scannen muss, nachdem man einen Artist eingetragen hat, sonst ist er nach zwei Refreshs einfach wieder weg? Hä?)
Natürlich kann ich in dem Interface auch direkt die Videos abspielen und zur Not den ganzen Tag loopen lassen, wie ich es aktuell natürlich mit unravel mache.
Von Kevin kam gerade eine Empfehlung für Ado rein und ich verbrachte den letzten Abend damit, mich einmal quer durch Youtube zu hören. Gefällt mir sehr gut!