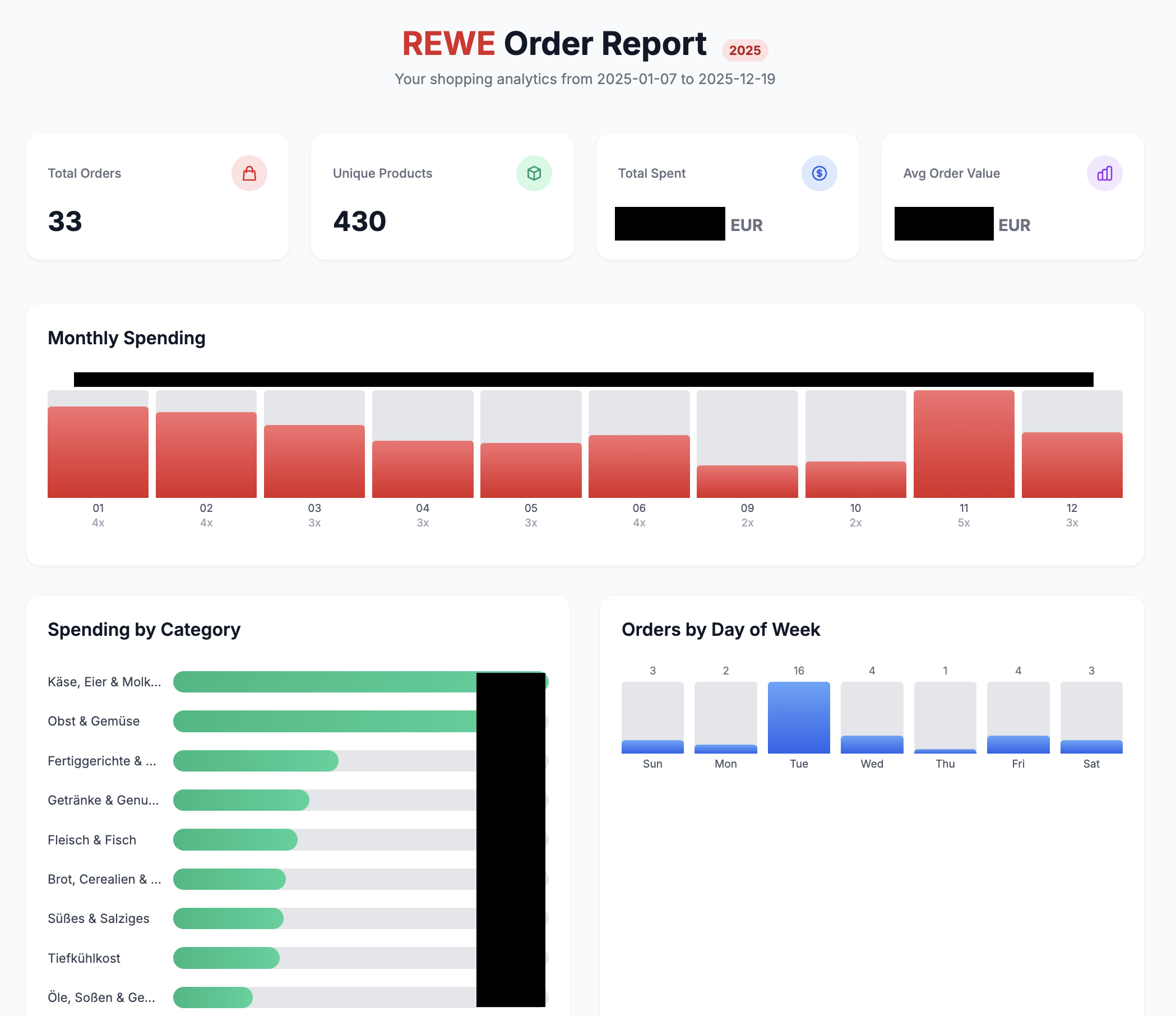
Wer meinen Jahresrückblick überflogen hat, wird sich vielleicht fragen, woher ich weiß, wie viele Liter Orangensaft ich im Jahr 2025 gekauft habe. Gerne beantworte ich das hier natürlich!
Tatsächlich ist es nämlich so, dass ich fast exklusiv über den REWE-Abholservice einkaufe. Das ist einfach so komfortabel. Ein bisschen klicken und am nächsten Tag holt man es einfach ab, ohne 90 Minuten lang durch den Supermarkt zu laufen. Nebenbei hat man auch noch den Vorteil, dass alle Bestellungen online abrufbar sind. Leider kann man sie nicht als CSV- oder JSON-Datei herunterladen, aber dafür können wir uns ja eben ein Script schreiben (lassen).
Ich habe das folgendermaßen gelöst: Zunächst einmal habe ich mich bei REWE eingeloggt und bin auf unter meinem Konto auf “Meine Einkäufe” gegangen. Dort habe ich jeden einzelnen Einkauf in einem neuen Tab geöffnet über “Details anzeigen”. Auf jedem der einzelnen Tabs habe ich mein von Claude erstelltes Bookmarklet gedrückt, das die Seite parst und als .json herunterläd. Ja, man hätte den Schritt vorher auch schon automatisieren können, aber die paar Tabs öffnen, hat mich jetzt auch nicht umgebracht.
Die heruntergeladenen .json-Files habe ich in einem Verzeichnis gesammelt und Claude gebeten, mir ein Python-Script zu schreiben, dass die Daten in eine SQLite-Datenbank importiert und daraus spannende und lustige Statistiken erstellt, in Form einer .html-Datei.
in this folder there are jsons with orders from my supermarket. build a sqlite database structure and import the json to then generate some statistics from it. there should be a script that returns some statistics like: most popular products, products with big price changes in the different purchases, etc. be creative
one last thing: please make an alternative script that does not generate console output, but a sleek looking web page (saved as report.html) with tailwind css (loaded from cdn)
Das war es auch schon. Lustige Statistiken! Vom groben überfliegen passte zahlenmäßig auch alles, nur mit den Zucchini hat er irgendwie Probleme, ich denke nicht, dass ich wirklich 80.000 Stück gegessen habe, vielleicht schaue ich mir das nächstes Jahr nochmal an.
Falls es jemand ausprobieren will, es wohnt auf Codeberg.
In regelmäßigen Abständen kopiere ich Dinge auf mein NAS. Backups, kennt ihr, ne? Bisher machte ich das immer mit einem relativ simplen rsync-Kommando:
rsync -aPr [quelle] /Volumes/dump/[ziel]
An sich funktionierte das auch, aber es war, sobald die Verzeichnisse größer wurden, z.B. dann 25.000 Fotos in meinem 2025er Lightroom-Katalog, dauerte es etwas, weil er natürlich bei jedem Bild erstmal prüft, ob es schon da ist, und ob es sich verändert hat und so weiter. Alles Dinge, die ich nicht brauche. Er soll einfach nur alle neuen Dateien auf die NAS bügeln und sich nicht soviel anstrengen.
rsync -a --ignore-existing --no-perms --no-owner --no-group --size-only --progress [quelle] /Volumes/dump/[ziel]
Nach etwas Diskussionen mit ChatGPT, bin ich mittlerweile bei diesem Kommando angekommen. Nach ersten Tests scheint das etwas schneller aber insgesamt ist es doch immer noch nervig langsam, vor allem bei tiefen, verschachtelten Verzeichnisstrukturen.
In einem kurzen Test habe ich gestern auch noch ausprobiert es mit unison zu lösen, da ich einen Weg suchte, wo er sich irgendwie merkt, was er beim letzten Mal rübergepeitscht hat, und beim Nächsten ausführen nur noch neue Dateien kopiert, ohne zu gucken, was auf dem Zielsystem schon vorhanden ist, aber so richtig zufriedenstellend und schnell funktionierte das leider auch nicht, da unison immer noch viel zu viele Vergleiche anstellt.
Entweder bin ich zu blöd, die richtige Lösung zu finden, oder sie existiert nicht. Die Alternativen wie restic, was ich für meine Server-Backups benutze, möchte ich hier nicht, da ich auf dem NAS eine 1:1-Kopie meiner Dateien als… Dateien haben will und nicht irgendein Repository mit de-duplizierten Datei-Chunks, die man erst wieder restoren muss.
Hat noch jemand eine Idee, wie man das beschleunigen könnte?
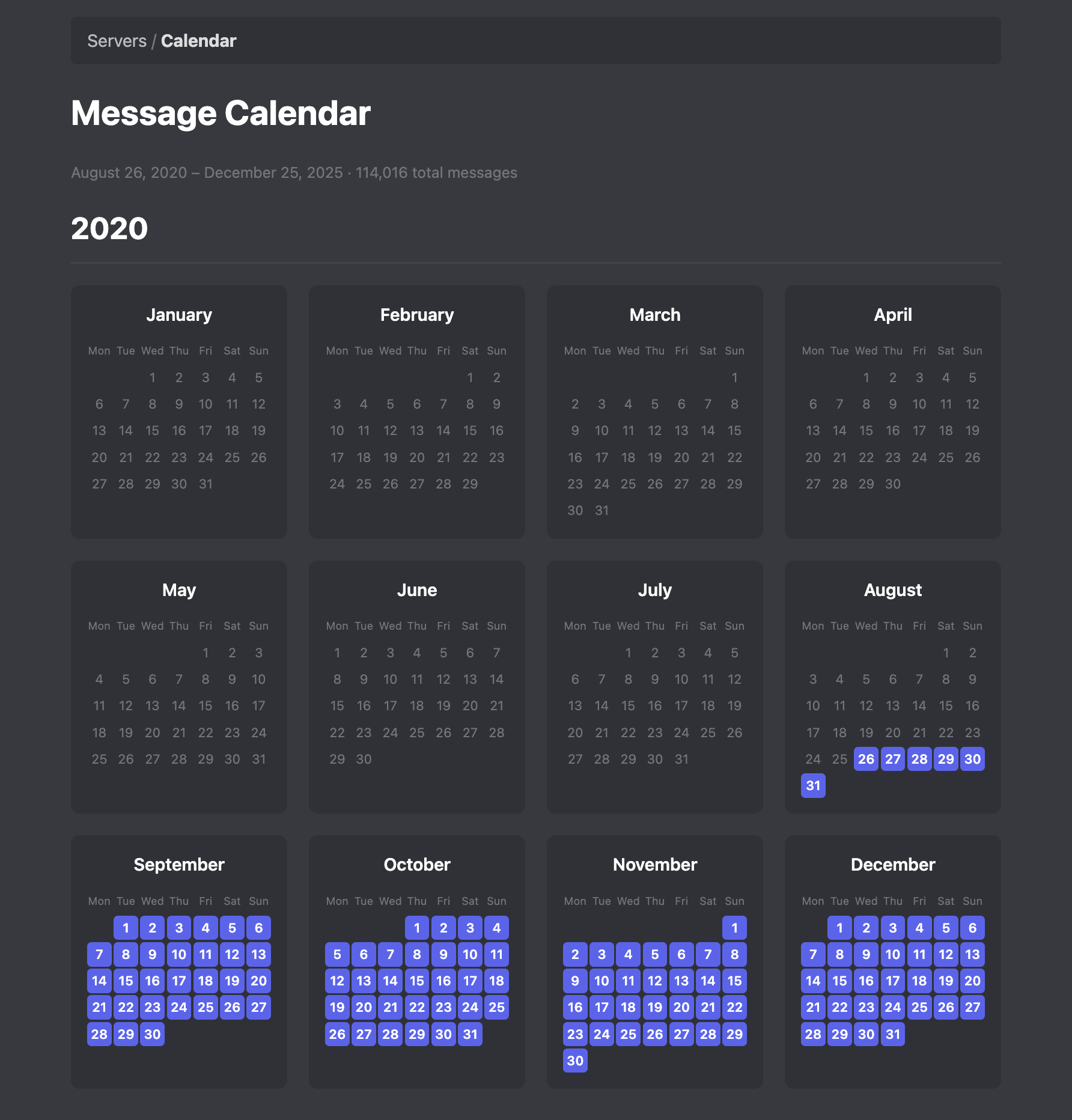
Wir hatten gestern den Need… Tage zu zählen, in einem Kalender. Erst wollte ich dafür ein Excel-Template raussuchen, doch ich ließ es schnell von Claude bauen, was wahrscheinlich weniger Zeit brauchte, als Numbers zu starten.
Falls ihr auch mal blaue und rote Tage zählen wollt, habe ich es unter tools.philippwaldhauer.com/calendar hochgeladen. Außerdem ist es auf Codeberg, da wollte ich mir eh mal einen Account machen, falls ich mal Lust habe, meine bedeutungslosen Repositories von Github zu entfernen.
Sobald ich mich von meinen Stars auf ein zehn Jahre altes, unbenutztes Projekt, verabschieden kann. :xheul:
Schon lange habe ich keine Art von Jahresrückblick mehr gepostet, aber es ist doch ganz witzig, also danke Torsten für die Inspiration, die ich hier direkt mal klaue.
Im Jahr 2025 habe ich…
Entertainment
…einen Film geguckt, und das war die Nackte Kanone, das Original von damals. Den Zweiten habe ich immerhin angefangen!
…vier Serienstaffeln geguckt.
…einmal versucht Anno 1602 zu spielen, aber nach wenigen Minuten aufgegeben.
…zwei Monate ein Shadow-Abo gehabt, aber nur einmal kurz gestartet, um Anno 1602 nicht zu spielen.
…drei Monate ein Geforce NOW-Abo gehabt, aber nie gestartet.
…einige viele Runden Agent Avenue gespielt, top Spiel!
…19 Bücher gelesen oder gehört. Das sind weniger als sonst, aber dafür waren vier Bände Tintenherz dabei und die sind ja echt lang, und auch mein Highlight in diesem Jahr.
…1.227 Stunden Podcasts gehört, wenn man den Overcast Listening-Stats vertrauen kann. Top Podcast: Apokalypse und Filterkaffee, aber die droppen auch einfach jeden Tag eine 60-Minuten-Folge.
…keine richtige Ahnung, wie viel neue Musik ich entdeckt und gehört habe, da ich fast nur Youtube nutzte und mein Spotify Wrapped wertlos ist.
Leben
…33x mal den Rewe (Abholservice) und 28x den Edeka besucht.
…wohl ungefähr 25x Bolognese, Chili oder Lasagne gekocht, da ich 25x mal Rügenwalder Mühle veganes Mühlen Hack kaufte. Kam mir häufiger vor.
…kein Einziges mal bei McDonalds oder Burger King gegessen, das ist ungewöhnlich!
…durchschnittlich 9.796 Schritte am Tag geschafft.
Content-Creation
…29.490 Fotos geschossen, das sind fast exakt genau so viel wie im letzten Jahr, verrückt. Die meisten entstanden mit dem Canon RF35mm/1.8 (20.000) und dem EF16-35mm/2.8 (8.000). Meine R6 hat damit schon über 85.000 Auslösungen, das hätte ich nicht erwartet.
…34 Blogposts geschrieben. Das sind zufällig so viele wie 2024 aber eigentlich natürlich zu wenig.
…fünf mal einen “Songs der Woche”-Post geschafft. Immerhin fast 10% des Jahres!
…an diversen kleinen Nebenprojekten gewerkelt, aber nichts veröffentlichbares produziert. Schade.
Telegram hat sich über die letzten Jahre ja in mein Leben geschlichen, gar nicht unbedingt, weil ich da so viele Kontakte habe, sondern weil die Bot-Schnittstelle so super einfach ist und weil die App unter iOS und MacOS so geschmeidig ist.
Im Zuge des Selfhosting-Wahns will man sich davon los sagen, aber es ist gar nicht so einfach. Ich hatte zwar mit Logsock ein Tool geschrieben, dass ich ähnlich leicht nutzen kann, aber leider geht der ganze Web-Push-Kram irgendwann nicht mehr, vor allem, wenn man die Web-App gar nicht mehr auf dem Homescreen haben will. Außerdem hatte ich in Telegram immer noch einen Bot, mit dem ich auch sprechen konnte, und einen Rückkanal hatte meine Webapp auch nicht.
Meine aktuelle Lösung ist nun ein selbst gehosteter Matrix-Server und Element X als App auf dem iPhone. Erst wollte ich den offiziellen Matrix-Server Synapse benutzen, aber alle Anleitungen, die ich dazu fand, waren relativ umfangreich und enthielten diverse andere Services, die ich, als künftiger Hoster eines Ein-Mann-Matrix-Servers sicherlich gar nicht brauche. Anscheinend ist auch Synapse an sich nicht gerade die leichtgewichtigste Variante.
Danke an Markus, der mir Continuwuity empfohlen hat. Das scheint sehr übersichtlich und benutzt z.B. kein schwergewichtiges Postgres als Datenbank. Meine docker-compose.yml enthält also nur zwei Kleinigkeiten:
Dieser Post könnte nun noch unbegrenzt lang werden, aber was soll ich sagen, it just works. Mit ein paar curl-Calls legt man sich schnell einen Admin und einen Bot-User an und kann dann, dank matrix-webhook mit einen einfachen POST-Request etwas in einen Raum schreiben lassen, toll!
Die Notifications kommen schnell in Element X an und die App fühlt sich auch recht gut an. Es ist kein Telegram, aber auf jeden Fall eine der besseren Open Source Chat-Apps. Es integriert sich auch gut genug ins System, dass mir Siri die eingehenden Notifications, wenn gewünscht, auch korrekt vorliest. Perfekt.
Im nächsten Schritt werde ich Claude wohl noch meine Telegram-Bots übersetzen lassen und ich bin wieder ein bisschen selbstständiger geworden, juchu!
Ja, ich weiß, die Notifications von Element X gehen am Ende natürlich wieder über einen Third Party Anbieter. Aber immerhin halt nicht mehr über Telegram-Infrastruktur
Kurz notiert, weil ich es alle drei Monate wieder vergesse, wie das Tool heißt, was ich benutze:
Mit osxphotos kann man seine Photos.app Library ganz einfach exportieren um sie z.B. auf die NAS zu schieben. Dabei werden alle möglichen Metadaten, soweit möglich, erhalten und mit exportiert.
Das versucht auch automatisch erstmal alle Originalversionen der Fotos herunterzuladen, was manchmal wohl etwas zu Problemen führen kann – bei mir zum Glück nicht, denn ich habe am Mac Keep Originals eh aktiviert.
In letzter Zeit versuche ich Kram, der mir schon seit längerem auf dem Herzen liegt, halbwegs schnell mit Hilfe von AI zu erledigen. Heute geht es es um eine kleine Webapp, die den Discord DSGVO-Export halbwegs übersichtlich anzeigt.
Warum?
Wozu brauche ich das? Ich versuche eigentlich jeden Tag ein paar Zeilen in mein Tagebuch zu schreiben, manchmal vergesse ich das aber und so entstehen unschöne Lücken. Wenn ich das Monate später bemerke, kann ich mich natürlich in den seltensten Fällen erinnern, was ich jetzt am 18. April 2025 genau getan habe.
Glücklicherweise gibt es eine gute Quelle, wo ich jeden Tag etwas reinschreibe, und meistens hat es auch eine gewisse Relevanz für den entsprechenden Tag: verschiedene Discord-Server.
Würde es sich nun wirklich nur um einzelne Tage handeln, könnte man wahrscheinlich mit der Suchfunktion in Discord alle eigenen Nachrichten von einem bestimmten Tag suchen, manchmal sind es aber doch ein paar Tage in Folge, die ich rekonstruieren muss, und so dachte ich mir schon länger, dass es spannend wäre, einfach den DSGVO-Export, der alle meine Nachrichten enthält, zu nehmen und entsprechend darzustellen, dass ich mich da kurz durchklicken kann.
Warum erst jetzt?
Ich glaube, meinen ersten Discord-Export habe ich vor zwei Jahren angefordert. Aber die Aufgabe war mir einfach immer zu dumm und zu lästig. Außerdem wusste ich ja, dass die Daten da sind, verarbeiten kann ich sie ja immer noch.
Prompts
Diese drei Prompts lieferten nach vielleicht so 10 Minuten das fertige Ergebnis, an dem ich nichts mehr zu mäkeln hatte. (Sonnet 4.5)
hey. in package/ there are a lot of json exports of the messages i send to different discord channels. please try to understand the schema and build an importer that imports the messages to a sqlite database. in a second step build a basic php app (no react, no stuff, just simple php multi page application) to view all the messages on the different channels and servers. the messages should be displayed grouped by day.
ok, good work so far. now create another entry page, that shows a calendar (yearly, all months, all days) from the start of the messages to the end. every day should be a link to a page that shows all messages for that day across all servers (oldest message at top, newest at bottom). also can you extend the importer to automatically download all the attachments and replace the links to the CDN with local links?
one small change: the day.php view currently displays all messages from the day. it would be better if they were grouped by CHANNEL and not completely jumbled
Fast 115k Nachrichten??
Fazit
Es ist irgendwie erfrischend, so kleine “könnte man ja mal machen” Sachen kurz abzugeben und am Ende ein benutzbares Produkt zu haben, ohne, dass man sich selber mit langweiligen JSON-Strukturen auseinander setzen muss.
Damit die 10 Minuten KI-Denkzeit nicht ganz umsonst waren, habe ich es auch mal bei Github hochgeladen, vielleicht muss ja noch jemand mal seinen Discord Export anschauen.
(Aber bitte nicht den Code, der sieht echt nach einer PHP-App von 2002 aus. Aber ich hab zumindest einmal drüber geguckt, ob er nicht zufällig alle meine Nachrichten irgendwo ins Internet schickt.)
Vor Monaten sah ich auf Mastodon einen Post von Nico, den ich mittlerweile nicht mehr wiederfinde, wahrscheinlich, weil er die Instanz zwischendurch gewechselt hat, der die HBO Max-Serie The Pitt anpries. Der Trailer wirkte ganz interessant, also schaute ich rein und muss sagen, dass ich selten von einer Serie so begeistert war!
Es gibt 15 Folgen, die den Verlauf einer 15-Stunden-Schicht in der Notaufnahme in einem Krankenhaus in Pittsburgh begleiten und es geht… hoch her. Das ist es auch irgendwie, was mir gefällt. Gefühlt kommt alle 4-5 Minuten ein neuer Patient oder eine neue Patientin reingerollt und stellt eine neue Herausforderung für Dr. Robby und sein Team dar. Es geht einfach Schlag auf Schlag und man hat gar keine Ruhe. Hier und da gibt es auch mal eine lustige Szene, oder es wird mal ein Hund gestreichelt, aber eigentlich ist konstant einfach Action.
Dr. Robby erinnerte mich an Anfang ganz ein wenig an House, aber naja, eigentlich ist er einfach nur ein bisschen grumpy, wer wäre das nicht, wenn man regelmäßig 15-stündige 100%-Stress Schichten schieben muss.
Was die einzelnen Fälle angeht, und was sonst so passiert, gewinnt es jetzt nicht unbedingt einen Preis für total Innovatives oder nie Dagewesenes. Ein paar Fälle sind mir auch etwas zu unsubtil und plakativ, wie die Fentanyl-Überdosis, oder die Frau, die von ihrer Menschenhändler-Vorgesetzten hingebracht wird, die für sie spricht, oder die Jugendliche, die gerne eine Abtreibung vornehmen will, aber in letzter Sekunde kommt ihre Mutter und versucht es zu verhindern, das sind jetzt alles keine ganz besonderen Sachen, wo es einen House braucht, um herauszufinden, was jetzt das Problem ist.
Manche Fälle sind aber auch spannender und tiefgründiger. Insgesamt ist es aber einfach die konstant hohe Schlagzahl von Dingen, Szenenwechseln, Patientenwechseln, die da passieren und irgendwie mitreißen. Ab und zu gibt es natürlich auch nochmal ein paar Sachen, die besonders unter die Haut gehen.
Also, top Serie, wenn man mal 15 Stunden nichts zu tun hat. Am besten vielleicht am Stück gucken, und sich freuen, dass man gerade auf dem Sofa sitzt und nicht wirklich in der Notaufnahme arbeitet.
Bis hierhin schrieb ich den Text, nachdem ich die ersten zehn Folgen in zwei oder drei Tagen durchgebinged hatte, danach gab es für mich leider einen kleinen Downer, der dazu führte, dass ich die Serie erstmal zwei Monate nicht weiter schaute. – Spoiler ab hier – In Folge 11 oder 12 kommt es nämlich auf einem Festival zu einem Mass Shooting und die ganzen Verletzten kommen in die Notaufnahme. Damit wird es für die ganze Crew natürlich nochmal herausfordernder, ganz abgesehen davon, dass eigentlich alle schon am Ende ihrer Schicht sind.
Gleichzeitig fand ich es schlagartig irgendwie anstrengend und langweilig. Statt einem neuen potentiell spannenden Fall, der Diagnostiziert werden muss, kommen nun pro Minute einfach drei Personen mit blutenden Schusswunden, und das ganze über 3 Folgen lang.
Wie gesagt, brauchte ich ein paar Wochen, bis ich mich dazu durchringen konnte, den Rest zu gucken und konnte mich mit der letzten Folge auch wieder mit allem etwas versöhnen.
In der Ursprungsversion dieses Textes schrieb ich noch, dass ich mir gar nicht gut vorstellen könnte, wie eine zweite Staffel der Serie aussehen würde, da in der ersten schon in einer solch massiven Schlagzahl alles passierte, was in einer Arzt-Serie passieren kann. Eben hab ich aber nochmal recherchiert und las, dass es anscheinend schon Anfang 2025 renewed wurde und die ersten Folgen der zweiten Staffel schon im Januar 2026 erscheinen werden. Nagut. Schauen wir mal, wie sich das entwickeln wird.
So ungefähr einmal im Jahr bekomme ich die Lust, mal einen CSV-Export von Outbank zu nehmen und ordentlich zu kategorisieren, um zu sehen, ob ich jetzt mehr oder weniger Geld für Essen ausgegeben habe. Bei meinem letzten Versuch machte ich das mit Firefly III, fand das aber nur so mittel und baute kurzerhand ein eigenes Tool dafür…
Da ich bei der Sache aber sehr nachlässig bin und schnell die Lust verliere, fehlten natürlich ein paar Sachen um es wirklich nutzen zu können und so begab es sich, dass ich wieder ungefähr anderthalb Jahre lang einfach nichts machte.
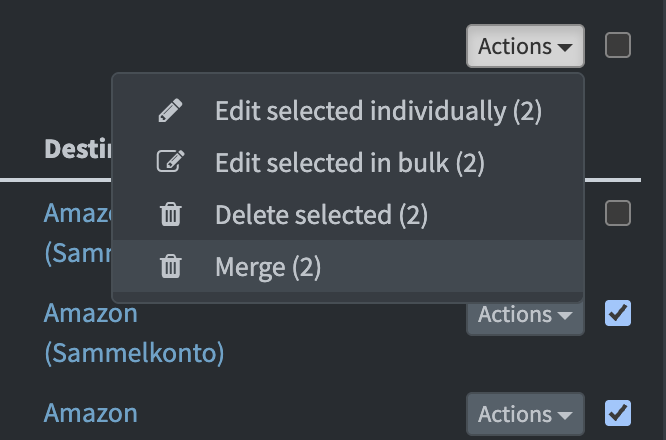
Da sich mein Tool also nicht benutzbar genug anfühlte, importiere ich wieder alles in Firefly und fing an alles durchzugehen. Irgendwann hat Amazon leider angefangen, teilweise für eine Bestellung von fünf Artikeln 4-6 Abbuchungen in völlig zufälligen Höhen zu machen. Da ich das alles etwas unübersichtlich fand, wollte ich die Transaktionen gerne zusammenführen, aber natürlich kann Firefly das nicht.
Nun stand ich vor der Frage, ob ich doch auf mein Tool wechsele, und herausfinde, was sonst noch fehlt um es wirklich benutzen zu können, oder ob ich es in Firefly einbaue. Vor dem KI-Zeitalter hätte ich mich garantiert für Ersteres entschieden, aber nun witterte ich die Chance, dass ein einfaches ”Bitte bau ein, dass man zwei oder mehr auf der Transaktionsliste ausgewählte Transaktionen mergen kann"* mein Problem in kurzer Zeit lösen könnte. Ich erstellte also einen Fork von Firefly, checkte das Git-Repo aus und warf Claude an. Insgesamt dauerte es so zehn Minuten AI-Zeit und weitere zehn Minuten für mich um herauszufinden, wie ich den Docker-Container bauen kann und das Feature war drin und funktioniert. Juchu!
Ein weiterer Fall in dem mir das vorsichtige anwenden von etwas AI-Magie den Alltag etwas erleichtert hat.
(Ja, ich weiß, theoretisch muss ich jetzt immer Zeit investieren, den Fork aktuell zu halten, mit den Updates aus Upstream, aber da kommt zum Einen eh nie was spannendes und zum Anderen hab ich davor mit der Version von zwei Jahren gearbeitet und nichts vermisst)
*: Der volle Prompt war etwas länger, auf Englisch und insgesamt gab es noch vier Feedbackloops, wo er ein paar Error 500s fixen musste.
Ich habe in den letzten Jahren ja öfters versucht wieder in die Scheibenwelt zu kommen, aber bisher ist es mir nicht so richtig gelungen. Ich finde das sehr schade da Wachen, Wachen! damals, als ich 16 war, das erste Buch war, was ich in meinem Leben gelesen habe und ich fand es total witzig und cool.
Leider scheint mit der Humor von Terry Pratchett in den letzten Jahren immer… weniger zu gefallen. Oder keine Ahnung. Ich habe, glaube ich, ungefähr schon dreimal mit Die Farben der Magie angefangen und es abgebrochen. Diesmal habe ich mir als Hörbuch angemacht und hab es fast durch, weil ich mich da weniger überwinden muss, als wenn ich selber lese, aber so richtig übergesprungen ist der Funken noch nicht wieder. Vielleicht gebe ich der Sache mal noch ein oder zwei Bücher. Vielleicht ist die Zauberer-Reihe auch einfach gar kein guter Einstieg und ich sollte lieber bei den Wachen-Büchern weiter machen. Wer weiß.
Diese gute alte Lesereihenfolge von Uwe Milde dürfte auf jeden Fall zu meinen ältesten Bookmarks gehören.